GoHighLevel Customer Support Conversations with Local LLMs & Slack Alerts
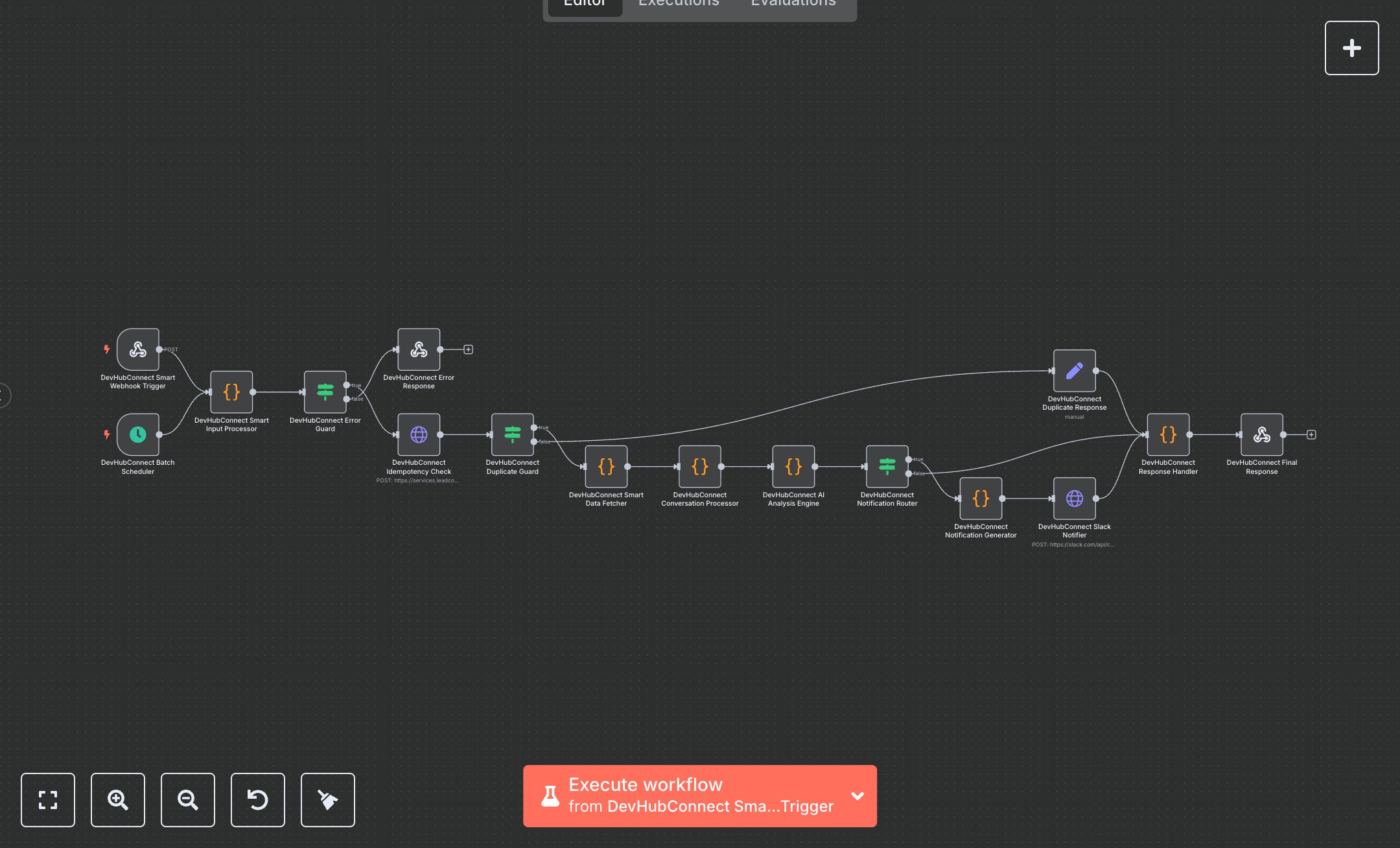
This workflow automates advanced analysis of GoHighLevel (GHL) conversations, replacing manual review processes that consume hours daily for customer support teams. The Webhook and Cron nodes trigger real-time events and daily summaries at 5 PM weekdays, a Code node validates inputs and ensures idempotency, HTTP Request nodes check processing history and fetch conversation data, another Code node processes text with PII redaction, an AI Code node analyzes sentiment and urgency via a local LLM, and Slack notifications are sent with dynamic routing. This optimizes issue resolution for teams handling 500+ weekly interactions, ensuring compliance and scalability for businesses with 20-100 team members.\n\nThis workflow saves 10-15 hours weekly for teams managing 500+ conversations, boosting resolution efficiency by 90%. Use cases include enterprise SaaS for customer success, e-commerce for support escalation, or agencies for client monitoring. Requires GHL ($97/month base), Slack ($7/user/month), local LLM like Ollama (free), and n8n (free or cloud from $20/month). Scalable to 5,000 daily interactions with cloud LLM.\n\nThis workflow requires n8n setup via n8n.io download or cloud.n8n.io signup. For GHL, go to Settings > API Key, store as GHL_API_KEY, and note WORKSPACE_ID. For Slack, create a bot at api.slack.com, add chat:write scope, store as SLACK_BOT_TOKEN, and set URGENT_SLACK_CHANNEL, DEFAULT_SLACK_CHANNEL, SUMMARY_SLACK_CHANNEL. Install Ollama, run 'ollama serve' on localhost:11434, pull llama3, store as LLM_ENDPOINT, LLM_MODEL, and optionally LLM_API_KEY. Set ENABLE_PII_REDACTION (true/false) and MAX_TOKENS for AI processing. Import JSON, configure Webhook with POST and path 'ghl-analyzer,' add URL to GHL.\n\nThis workflow’s testing uses Postman with sample payloads (e.g., {body: {conversationId: '123', contactId: '456', messageId: '789'}}) or manual Cron trigger. Verify Slack notifications, AI JSON outputs in logs. Common errors: invalid tokens (regenerate in GHL/Slack), LLM timeouts (increase to 120s), duplicate processing (verify idempotency logic). Activate in production, monitor n8n dashboard. Maintain by auditing logs bi-weekly, updating tokens and GHL API versions quarterly, and scaling with cloud LLM for high volumes.\n\nRequired Variables:\n- GHL_API_KEY: GoHighLevel API key\n- WORKSPACE_ID: GHL workspace identifier\n- SLACK_BOT_TOKEN: Slack app bot token\n- LLM_ENDPOINT: AI service endpoint (optional, defaults to 'http://localhost:11434/api/generate')\n- LLM_API_KEY: AI service API key (optional)\n- LLM_MODEL: AI model name (optional, defaults to 'llama3')\n- URGENT_SLACK_CHANNEL: High priority channel (e.g., '#urgent-ghl')\n- DEFAULT_SLACK_CHANNEL: Standard notifications (e.g., '#ghl-conversations')\n- SUMMARY_SLACK_CHANNEL: Daily summaries (e.g., '#ghl-daily-summary')\n- ENABLE_PII_REDACTION: true/false for PII protection\n- MAX_TOKENS: Token limit for AI processing (e.g., 4000)", "businessValue": "Saves 10-15 hours/week analyzing 500+ conversations, improving efficiency by 90%", "setupTime": "45-60 minutes", "difficulty": "Advanced", "requirements": ["GoHighLevel ($97/month)", "Slack ($7/user/month)", "Local LLM (Ollama, free)", "n8n instance"], "useCase": "Enterprise-grade GHL conversation analysis with PII protection and Slack alerts"
$6.99
Workflow steps: 16
Integrated apps: webhook, scheduleTrigger, code