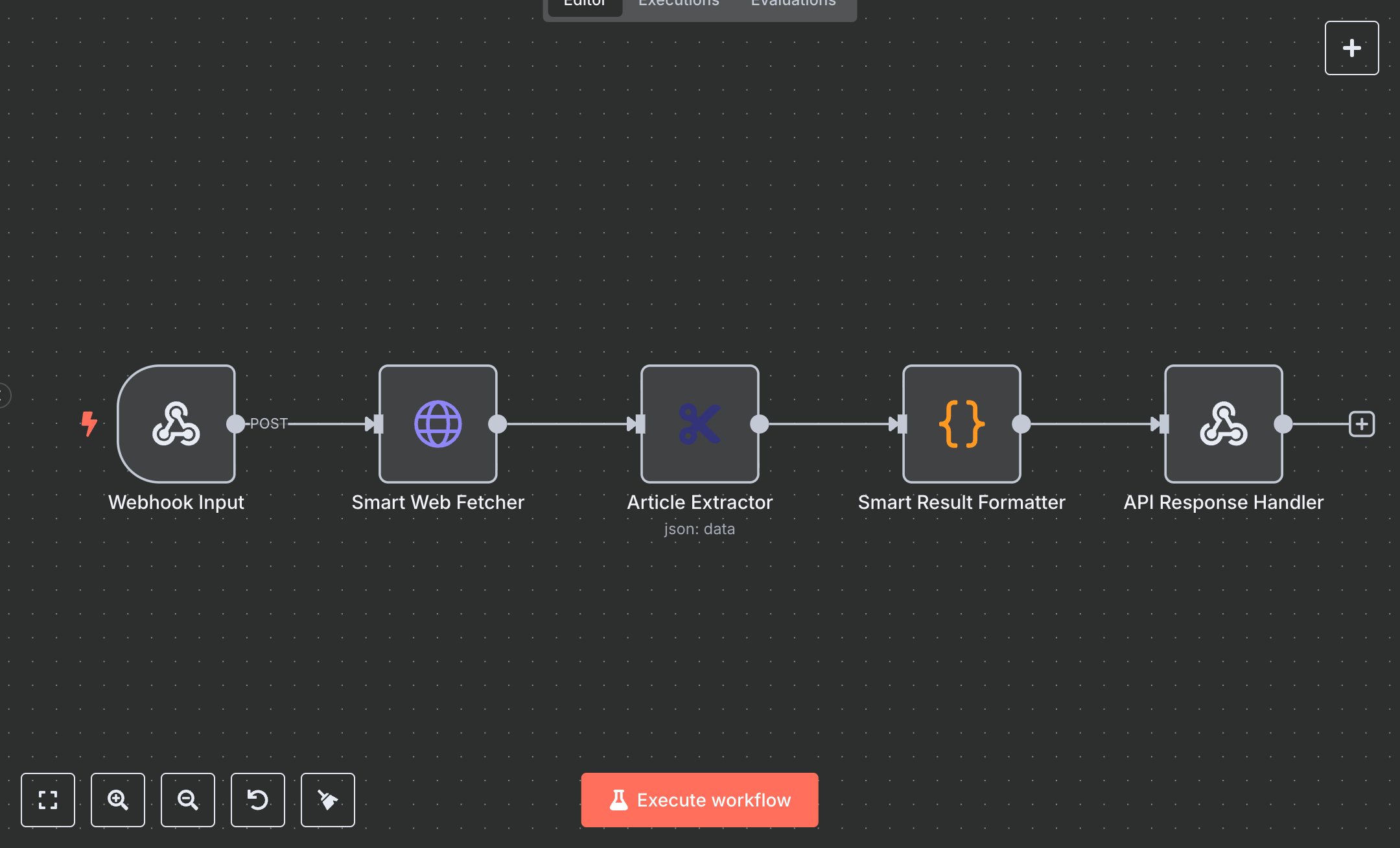
Web Article Scraper: Content Extraction
This workflow automates web article scraping via an API endpoint, replacing manual content extraction that consumes 10+ hours weekly for teams processing 50+ web pages monthly. It accepts POST requests with a target URL, fetches web content, extracts article titles and links using robust CSS selectors, deduplicates results, and returns structured JSON responses. Key nodes include Webhook (Webhook Input) for API requests, HTTP Request (Smart Web Fetcher) for page retrieval, HTMLExtract (Article Extractor) for content parsing, Code (Smart Result Formatter) for processing and deduplication, and RespondToWebhook (API Response Handler) for output. Ideal for content teams, researchers, or marketers (3-10 staff) in media, SEO, or research ($500K-$5M revenue), it reduces extraction time by 90% for 50-500 pages monthly.\n\nSaves 8 hours/week on 50+ pages, improving extraction speed by 90%. Suits content aggregation, SEO analysis, or research automation. Requires n8n ($20/month cloud). Scalable to 1,000 pages/month; needs HTTPS.\n\nSetup Instructions:\n1. Install n8n via cloud.n8n.io or self-host (docker run -it --rm -p 5678:5678 n8nio/n8n).\n2. Configure webhook (https://your-n8n.app/webhook/scrape-articles) for POST requests.\n3. No external APIs required, but ensure stable internet for HTTP requests.\n4. Set environment variable: N8N_HOST for webhook URL.\n\nTesting:\n- POST {url: 'https://example.com/blog', maxArticles: 10} to webhook. Verify response with article titles, URLs, and metadata.\n- Test invalid input: POST {url: 'invalid'}. Check error response with VALIDATION_ERROR.\n- Test no articles: POST {url: 'https://example.com/empty'}. Verify EXTRACTION_ERROR response.\n\nErrors:\n- 400 (invalid URL, ensure url is valid HTTP/HTTPS).\n- 500 (fetch or processing error, check network or page structure).\n- No articles extracted (incompatible page, update CSS selectors in Article Extractor).\n\nMaintenance:\n- Monitor n8n logs for HTTP request failures.\n- Update CSS selectors in Article Extractor quarterly for new website structures.\n- Check webhook performance monthly for scalability.\n\nOptimization:\n- Expand CSS selectors in Article Extractor for specific websites.\n- Add caching in Smart Result Formatter to reduce redundant fetches.\n- Integrate Google Sheets or database for storing results.", "businessValue": "Saves 8 hours/week on 50+ pages with 90% faster extraction", "setupTime": "20-30 minutes", "difficulty": "Intermediate", "requirements": [ "n8n cloud ($20/month) or self-hosted", "Stable HTTPS connection", "Environment variable: N8N_HOST" ], "useCase": "Automating web article title and link extraction via API for content aggregation"
$5.49
Workflow steps: 5
Integrated apps: webhook, httpRequest, htmlExtract