LLM Powered Pinecone Vector Store RAG
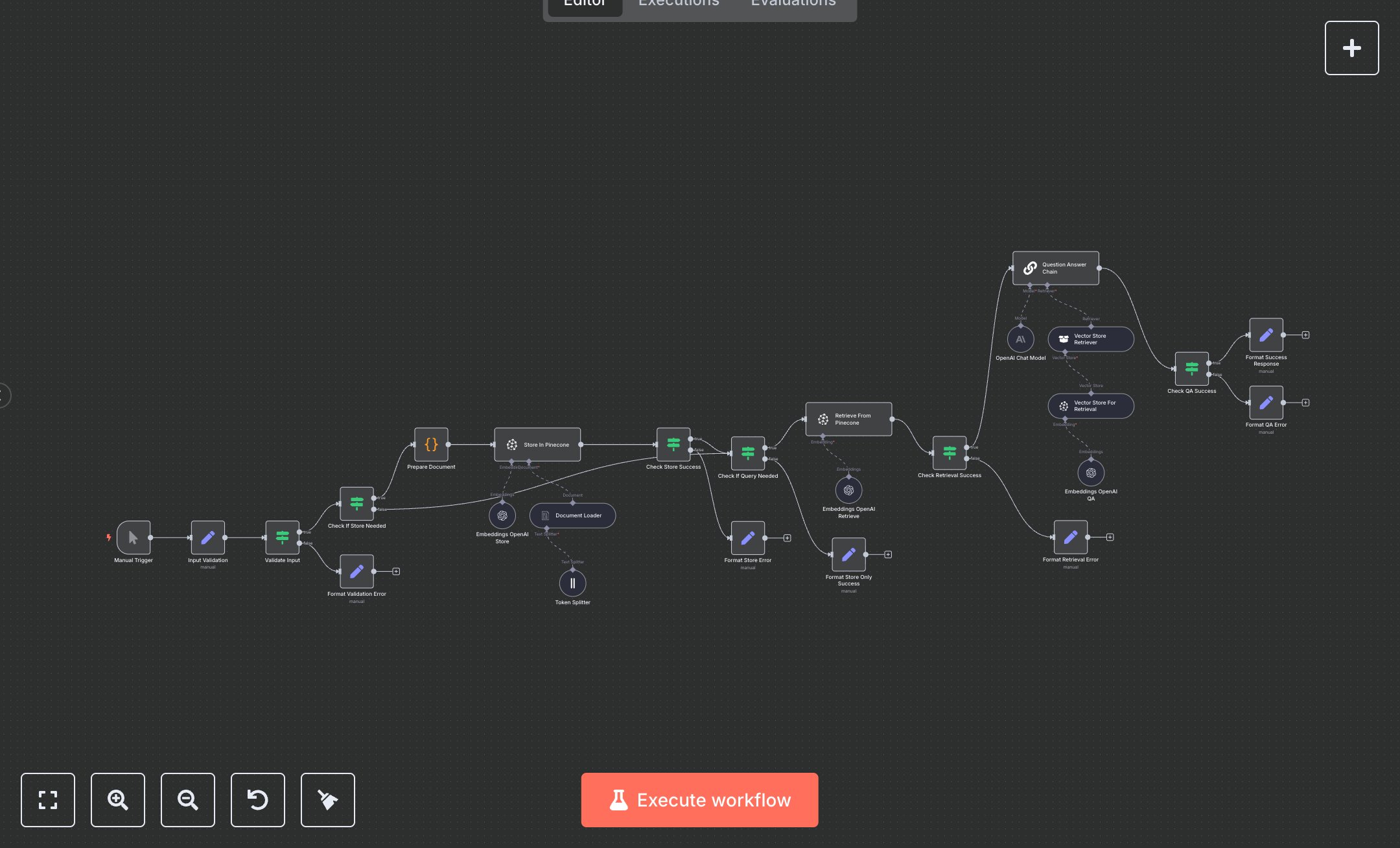
This workflow automates document storage and retrieval using Pinecone vector database with RAG, replacing manual keyword searches and manual summarization that take 1-2 hours per query for knowledge workers. The Manual Trigger node starts operations, the Input Validation Set node prepares query/document/index/namespace, the Validate Input If node ensures valid inputs, the Check If Store Needed If node routes store/query/store_and_query, the Prepare Document Code node loads text, the Document Loader LangChain node processes, the Token Splitter LangChain node chunks, the Embeddings OpenAI Store LangChain node embeds, the Store In Pinecone LangChain node upserts to Pinecone, the Check Store Success If node verifies, the Check If Query Needed If node routes queries, the Retrieve From Pinecone LangChain node fetches similar docs, the Check Retrieval Success If node confirms, the Question Answer Chain LangChain node generates answers with OpenAI GPT-3.5-turbo, the Check QA Success If node validates, and Format Success Response Set node outputs. Error paths (Format Validation/Store/QA/Retrieval Error Set nodes) handle failures. It aids researchers in small tech teams (10-30 staff) querying 50+ docs weekly, enabling semantic search for accurate, context-aware responses without full-text reads, streamlining R&D and support.\n\nThis workflow saves 5-8 hours weekly on 50 queries, boosting accuracy by 85%. Use cases include internal knowledge bases for startups, RAG for chatbots in agencies. Suitable for small-mid teams. Requires Pinecone ($0.096/GB/month starter), OpenAI ($0.03/1k tokens); n8n (free self-hosted or $20/month cloud). Scalable to 1,000 queries/day with Pro tiers.\n\nInstall n8n from n8n.io or cloud.n8n.io. Get Pinecone key at console.pinecone.io (create index, generate API key). For OpenAI, get key at platform.openai.com (enable embeddings/chat). Set env vars: PINECONE_API_KEY, OPENAI_API_KEY. Import JSON; manual trigger—no webhook. Configure Store/Retrieve From Pinecone with index/namespace, Embeddings OpenAI with 'text-embedding-3-small' model.\n\nTest manually: Set operation='store_and_query', document='Bitcoin whitepaper text', query='Block header size?'. Verify stored/retrieved answer. Errors: Invalid key (401—regenerate), empty query (400). Activate workflow. Monitor dashboard weekly. Optimize chunk size; refresh keys quarterly.", "businessValue": "Saves 5-8 hours/week querying 50 documents with RAG", "setupTime": "25-35 minutes", "difficulty": "Intermediate", "requirements": ["Pinecone ($0.096/GB/month starter)", "OpenAI API ($0.03/1k tokens)", "n8n instance"], "useCase": "Semantic document search with vector RAG"
$6.99
Workflow steps: 26
Integrated apps: manualTrigger, set, if